L'intelligence artificielle est très souvent parée de toutes les vertus ou accusée de tous les dangers mais le problème centrale est de savoir de quoi on parle.


La principale difficulté est de savoir de quoi on parle tant sa définition et son champ d'application restent flous, parfois soumis à des abus de sens ou même de fantasmes sur ses dangers supposés. Cette difficulté tient au fait que l'intelligence artificielle ne repose pas sur des techniques ou moyens propres et identifiables mais sur des moyens existants qui sont les techniques d'apprentissage, les systèmes informatiques avec des puissances de traitements considérables et de plus en plus importantes avec les progrès de l'électronique et l'accès à des logiciels utilisant à plein les possibilités des algorithmes.

La premières clarification consiste à bien savoir ce qui est logiciel algorithmique et intelligence artificielle, ce qui n'est pas forcément aisé tant la situation actuelle est confuse (et va le rester sans doute encore longtemps). Tout ce qui fait uniquement appel à des capacités de traitement, ces capacités fussent-elles considérables, ne relèvent aucunement de l'IA.

Traitements des données et du langage
Par exemple, on peut dire que les traducteurs automatiques ne relèvent pas en général de l'IA à moins qu'ils n'aient pour but la traduction d'un poème de Verlaine... et on n'en est pas encore là, même avec l'IA. Il s'agit donc de savoir de quelle traduction il s'agit : plus on ira vers la traduction de concepts, plus on aura recours à l'IA.
En matière de langage, un mot peut avoir plusieurs connotations. Par exemple, le mot SERVICE a plusieurs significations : militaire, restauration... et seul le contexte permet de choisir l’occurrence adéquate, à l’aide d’outils algorithmiques comme le réseau de neurones récurrents. [1] On utilise ensuite les techniques d’apprentissage pour adapter la réponse à l’usager à travers une base qui contient un stock de réponses possibles.

Illustration vectorielle de l'IA
Autre exemple, celui des Ressources humaines avec un logiciel dédié à la prédiction du roulement (ou turn over) dans l’entreprise pour éviter un surplus de démissions.
Les données de départ liées à la problématique regroupent le salaire,
la date d’embauche, les notes d’évaluation et la satisfaction et doivent
être corrélées avec le risque de démission. On utilise pour cela un
algorithme comme le diagramme d’arbres décisionnels qui combinent les données pour proposer un résultat.
L'apprentissage,
d'une façon simple, est le processus mental échec-réussite qui permet
par exemple dans un problème de labyrinthe, de procéder par tentatives
jusqu'à parvenir à la solution adéquate.



L'IA repose sur la notion d'apprentissage
: l'objectif est de parvenir à ce qu'un système soit capable d'intégrer
de nouvelles données afin qu'il puisse être capable de réagir à une
situation inédite pour lui. Pour cela, outre des puissance de traitement
considérables, il a besoin de deux choses :
- d'une programmation dynamique reposant sur de puissants langages, incluant boucles itératives et algorithmiques;
- de bases de données dynamiques
à haut degré d'accès, reposant sur des mémoires électroniques super
performantes ou sur des mémoires à cristaux, et dynamiques, c'est-à-dire
capables d'être interconnectées à d'autres bases de données pour y
puiser les données pertinentes qui lui manquent.
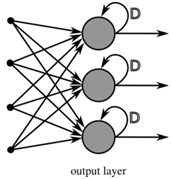 Réseau de neurones récurrents
Réseau de neurones récurrents
Si tout langage de programmation peut être en principe utilisé en IA, certains y sont mieux adaptés comme Java ou Python qui comprend de nombreuses librairies, dont certaines dédiées comme Scikit-Learn pour le machine learning et TensorFlow pour le Deep Learning.


IA et algorithmie
Dans le cas du jeu d'échecs dont il est souvent question dans les médias, l'ordinateur-joueur puise dans sa base de données pour contrer son adversaire, en fonction de l'historique stockée dans la base (les méthodes, les parties antérieures importantes, les "coups" répertoriés... et même les techniques, les habitudes de tel ou tel joueur).
Les possibilités de
l'ordinateur-joueur (et ses chances de victoire) seront donc déterminées
par l'étendue des données détenues dans la base. Une base qui pourra
bien sûr évoluer, être mise à jour au fil des années. Mais ceci au
détriment de la vitesse de traitement... qui est considérable mais a
aussi ses limites.

l'IA & la génération d'images
L'IA intervient vraiment en mettant en relations deux ou plusieurs bases dont certaines données combinées à l'aide d'un algorithme vont pouvoir donner naissance à de nouvelles combinaisons qui vont surprendre l'adversaire, puis être sauvegardées dans la base pour l'enrichir. C'est un processus d'apprentissage dont les interactions finissent par dégager une solution (qui dans un premier temps n'est pas forcément la plus optimale).


Mais dans ce processus, plusieurs types d’erreurs peuvent survenir :
- Sur les données : manque de tests, hypothèses et critères trop vagues, mal dimensionnés ;
- Matériel sous dimensionné par rapport aux objectifs ;
- La complexité des systèmes d’IA comme les réseaux de neurones, le nombre de paramètres utilisés font qu’il est très malaisé de comprendre les sources d’erreurs.
Notes et références
[1] Dans une première approche, on peut dire que les réseaux de neurones récurrents (en anglais récurrent neural networks ou
RNNs), représentent une classe de réseaux de neurones permettant aux
prédictions antérieures d'être utilisées comme entrées, à travers des
états non directement accessibles ou états cachés.